Redis源码学习笔记 学习来源:redis-2.8
1 源码结构 以redis-2.8为例:
来源:古明地盆
1.1 目录 1.1.1 deps 这个目录主要包含了 Redis 依赖的第三方代码库 ,包括 Redis 的 C 语言版本客户端代码 hiredis、jemalloc 内存分配器代码、readline 功能的替代代码 linenoise,以及 lua 脚本代码。这部分代码的一个显著特点就是它们可以独立于 Redis src 目录下的功能源码进行编译,也就是说它们可以独立于 Redis 存在和发展。
1.1.2 src 这个目录里面包含了 Redis 所有功能模块的代码文件。
因为 Redis 的功能模块实现是典型的 C 语言风格,不同功能模块之间不再设置目录分隔,而是通过头文件包含来相互调用 。这样的代码风格在基于 C 语言开发的系统软件中也比较常见,比如 Memcached 的源码文件也是在同一级目录下。
1.1.3 tests Redis 实现的测试代码可以分成四部分,分别是单元测试(对应 unit 子目录),Redis Cluster 功能测试(对应 cluster 子目录)、哨兵功能测试(对应 sentinel 子目录)、主从复制功能测试(对应 integration 子目录)。这些子目录中的测试代码使用了 Tcl 语言(通用的脚本语言)进行编写,主要目的就是方便进行测试。
1.1.4 utils 在 Redis 开发过程中,还有一些功能属于辅助性功能,包括用于创建 Redis Cluster 的脚本、用于测试 LRU 算法效果的程序,以及可视化 rehash 过程的程序。在 Redis 代码结构中,这些功能代码都被归类到了 utils 目录中统一管理。
除了 deps、src、tests、utils 四个子目录以外,Redis 源码总目录下其实还包含了两个重要的配置文件,一个是 Redis 实例的配置文件 redis.conf,另一个是哨兵的配置文件 sentinel.conf。当你需要查找或修改 Redis 实例或哨兵的配置时,就可以直接定位到源码主目录下。
1.2 功能模块 Redis 代码结构中的 src 目录,包含了实现功能模块的 123 个代码文件,Redis 服务端的所有功能实现都在这里面。在这 123 个代码文件中,对于某个功能来说,一般包括了实现该功能的源文件(.c 文件) 和对应的头文件(.h 文件),比如 dict.c 和 dict.h 就是用于实现哈希表的 C 文件和头文件。
1.2.1 服务器实例
1.2.2 数据类型和结构
1.2.3 高可靠和高可扩展
数据持久化
Redis 的数据持久化实现有两种方式:内存快照 RDB 和 AOF 日志,分别实现在了 rdb.h/rdb.c 和 aof.c 中。
注意,在使用 RDB 或 AOF 对数据库进行恢复时,RDB 和 AOF 文件可能会因为 Redis 实例所在服务器宕机,而未能完整保存,进而会影响到数据库恢复。因此针对这一问题,Redis 还实现了对这两类文件的检查功能,对应的代码文件分别是 redis-check-rdb.c 和 redis-check-aof.c。
主从复制实现
Redis 把主从复制功能实现在了 replication.c 文件中,另外你还需要知道的是,Redis 的主从集群在进行恢复时,主要是依赖于哨兵机制,而这部分功能则直接实现在了 sentinel.c 文件中。其次,与 Redis 实现高可靠性保证的功能类似,Redis 高可扩展性保证的功能,是通过 Redis Cluster 来实现的,这部分代码也非常集中,就是在 cluster.h/cluster.c 代码文件中。
2 数据结构 2.1 简单动态字符串 源码文件:sds.c,sds.h
这里只分析SDS的定义,创建和释放,其他操作都是对string.h的进一步封装。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #ifndef __SDS_H #define __SDS_H #include <sys/types.h> #include <stdarg.h> typedef char *sds; struct sdshdr { unsigned int len; unsigned int free ; char buf[]; }; static inline size_t sdslen (const sds s) { struct sdshdr *sh =void *)(s-(sizeof (struct sdshdr))); return sh->len; } static inline size_t sdsavail (const sds s) { struct sdshdr *sh =void *)(s-(sizeof (struct sdshdr))); return sh->free ; } #endif
内联函数sdslen和sdsavail都是对sds进行操作(注意不是普通的C字符串),换句话说,sds存在于已经创建好的结构体sdshdr中。
以sdslen为例,注意到:
1 struct sdshdr *sh =void *)(s-(sizeof (struct sdshdr)));
sds(本质是char *的别名)指向buf数组的首地址 ,因此,用sds减去sdshdr结构体的定长部分(len和free的空间大小之和)得到的地址就是sdshdr结构体的首地址,再强转为void *,因此可以赋值给struct sdshdr *的指针。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 sds sdsempty (void ) { return sdsnewlen("" ,0 ); } sds sdsnew (const char *init) { size_t initlen = (init == NULL ) ? 0 : strlen (init); return sdsnewlen(init, initlen); } sds sdsdup (const sds s) { return sdsnewlen(s, sdslen(s)); } void sdsfree (sds s) { if (s == NULL ) return ; zfree(s-sizeof (struct sdshdr)); }
注意到,上述函数均调用了sds.c/sdsnewlen函数,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 sds sdsnewlen (const void *init, size_t initlen) { struct sdshdr *sh ; if (init) { sh = zmalloc(sizeof (struct sdshdr)+initlen+1 ); } else { sh = zcalloc(sizeof (struct sdshdr)+initlen+1 ); } if (sh == NULL ) return NULL ; sh->len = initlen; sh->free = 0 ; if (initlen && init) memcpy (sh->buf, init, initlen); sh->buf[initlen] = '\0' ; return (char *)sh->buf; }
其中,zmalloc和zcalloc是对malloc和calloc的封装,现在来分析:
1 sh = zmalloc(sizeof (struct sdshdr)+initlen+1 );
注意sdshdr为变长结构体,sizeof(struct sdshdr)为成员len和free分配了空间,initlen+1则为buf[]分配了空间,其中initlen为有效长度,1为空字符的空间。
1 memcpy (sh->buf, init, initlen);
将地址init开始的initlen字节复制到sh->buf。
memcpy函数原型如下:
1 void *memcpy (void *dest, const void *src, size_t num ) ;
memcpy 会复制 src 所指的内存内容的前 num 个字节到 dest 所指的内存地址上。memcpy 并不关心被复制的数据类型(因此都是void *,只要是地址就行),只是逐字节地进行复制,这给函数的使用带来了很大的灵活性,可以面向任何数据类型进行复制。
从long long创建sds:
1 2 3 4 5 6 sds sdsfromlonglong (long long value) { char buf[SDS_LLSTR_SIZE]; int len = sdsll2str(buf,value); return sdsnewlen(buf,len); }
其中又调用了sdsll2str,该函数才是真正将long long转换成字符串:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #define SDS_LLSTR_SIZE 21 int sdsll2str (char *s, long long value) { char *p, aux; unsigned long long v; size_t l; v = (value < 0 ) ? -value : value; p = s; do { *p++ = '0' +(v%10 ); v /= 10 ; } while (v); if (value < 0 ) *p++ = '-' ; l = p-s; *p = '\0' ; p--; while (s < p) { aux = *s; *s = *p; *p = aux; s++; p--; } return l; }
注意语句:
右侧‘0’+(v%10)的作用是将v的末尾数字转换成ASCII码表示的单字符数字。
左侧*p++,*的优先级大于++,因此执行顺序为:
2.2 链表 源码文件:adlist.c,adlist.h
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 #ifndef __ADLIST_H__ #define __ADLIST_H__ typedef struct listNode { struct listNode *prev ; struct listNode *next ; void *value; } listNode; typedef struct listIter { listNode *next; int direction; } listIter; typedef struct list { listNode *head; listNode *tail; void *(*dup)(void *ptr); void (*free )(void *ptr); int (*match)(void *ptr, void *key); unsigned long len; } list ; #define listLength(l) ((l)->len) #define listFirst(l) ((l)->head) #define listLast(l) ((l)->tail) #define listPrevNode(n) ((n)->prev) #define listNextNode(n) ((n)->next) #define listNodeValue(n) ((n)->value) #define listSetDupMethod(l,m) ((l)->dup = (m)) #define listSetFreeMethod(l,m) ((l)->free = (m)) #define listSetMatchMethod(l,m) ((l)->match = (m)) #define listGetDupMethod(l) ((l)->dup) #define listGetFree(l) ((l)->free) #define listGetMatchMethod(l) ((l)->match) #define AL_START_HEAD 0 #define AL_START_TAIL 1 #endif
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 #include <stdlib.h> #include "adlist.h" #include "zmalloc.h" list *listCreate (void ) { struct list *list ; if ((list = zmalloc(sizeof (*list ))) == NULL ) return NULL ; list ->head = list ->tail = NULL ; list ->len = 0 ; list ->dup = NULL ; list ->free = NULL ; list ->match = NULL ; return list ; } void listRelease (list *list ) { unsigned long len; listNode *current, *next; current = list ->head; len = list ->len; while (len--) { next = current->next; if (list ->free ) list ->free (current->value); zfree(current); current = next; } zfree(list ); } list *listAddNodeHead (list *list , void *value) { listNode *node; if ((node = zmalloc(sizeof (*node))) == NULL ) return NULL ; node->value = value; if (list ->len == 0 ) { list ->head = list ->tail = node; node->prev = node->next = NULL ; } else { node->prev = NULL ; node->next = list ->head; list ->head->prev = node; list ->head = node; } list ->len++; return list ; } list *listAddNodeTail (list *list , void *value) { listNode *node; if ((node = zmalloc(sizeof (*node))) == NULL ) return NULL ; node->value = value; if (list ->len == 0 ) { list ->head = list ->tail = node; node->prev = node->next = NULL ; } else { node->prev = list ->tail; node->next = NULL ; list ->tail->next = node; list ->tail = node; } list ->len++; return list ; } list *listInsertNode (list *list , listNode *old_node, void *value, int after) { listNode *node; if ((node = zmalloc(sizeof (*node))) == NULL ) return NULL ; node->value = value; if (after) { node->prev = old_node; node->next = old_node->next; if (list ->tail == old_node) { list ->tail = node; } } else { node->next = old_node; node->prev = old_node->prev; if (list ->head == old_node) { list ->head = node; } } if (node->prev != NULL ) { node->prev->next = node; } if (node->next != NULL ) { node->next->prev = node; } list ->len++; return list ; } void listDelNode (list *list , listNode *node) { if (node->prev) node->prev->next = node->next; else list ->head = node->next; if (node->next) node->next->prev = node->prev; else list ->tail = node->prev; if (list ->free ) list ->free (node->value); zfree(node); list ->len--; } listIter *listGetIterator (list *list , int direction) { listIter *iter; if ((iter = zmalloc(sizeof (*iter))) == NULL ) return NULL ; if (direction == AL_START_HEAD) iter->next = list ->head; else iter->next = list ->tail; iter->direction = direction; return iter; } void listReleaseIterator (listIter *iter) { zfree(iter); } listNode *listNext (listIter *iter) { listNode *current = iter->next; if (current != NULL ) { if (iter->direction == AL_START_HEAD) iter->next = current->next; else iter->next = current->prev; } return current; }
2.3 字典 重要的结构体:
dictEntry:键值对,或称为哈希节点
dictht:哈希表,包含键值对dictEntry
dict:字典,包含两个哈希表dictht
2.3.1 头文件 源码文件在dict.h和dict.c
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 #include <stdint.h> #ifndef __DICT_H #define __DICT_H #define DICT_OK 0 #define DICT_ERR 1 #define DICT_NOTUSED(V) ((void) V) typedef struct dictEntry { void *key; union { void *val; uint64_t u64; int64_t s64; double d; } v; struct dictEntry *next ; } dictEntry; typedef struct dictType { unsigned int (*hashFunction) (const void *key) ; void *(*keyDup)(void *privdata, const void *key); void *(*valDup)(void *privdata, const void *obj); int (*keyCompare)(void *privdata, const void *key1, const void *key2); void (*keyDestructor)(void *privdata, void *key); void (*valDestructor)(void *privdata, void *obj); } dictType; typedef struct dictht { dictEntry **table; unsigned long size; unsigned long sizemask; unsigned long used; } dictht; typedef struct dict { dictType *type; void *privdata; dictht ht[2 ]; long rehashidx; int iterators; } dict; #define DICT_HT_INITIAL_SIZE 4 extern dictType dictTypeHeapStringCopyKey;extern dictType dictTypeHeapStrings;extern dictType dictTypeHeapStringCopyKeyValue;#endif
2.3.2 实现
1 2 3 4 5 6 7 8 9 10 11 12 dict *dictCreate (dictType *type, void *privDataPtr) { dict *d = zmalloc(sizeof (*d)); _dictInit(d,type,privDataPtr); return d; }
又调用了_dictInit初始化字典:
1 2 3 4 5 6 7 8 9 10 11 12 13 int _dictInit(dict *d, dictType *type, void *privDataPtr) { _dictReset(&d->ht[0 ]); _dictReset(&d->ht[1 ]); d->type = type; d->privdata = privDataPtr; d->rehashidx = -1 ; d->iterators = 0 ; return DICT_OK; }
其中又调用了_dictReset对哈希表进行重置:
1 2 3 4 5 6 7 8 static void _dictReset(dictht *ht) { ht->table = NULL ; ht->size = 0 ; ht->sizemask = 0 ; ht->used = 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 int dictRehash (dict *d, int n) { if (!dictIsRehashing(d)) return 0 ; while (n--) { dictEntry *de, *nextde; if (d->ht[0 ].used == 0 ) { zfree(d->ht[0 ].table); d->ht[0 ] = d->ht[1 ]; _dictReset(&d->ht[1 ]); d->rehashidx = -1 ; return 0 ; } assert(d->ht[0 ].size > (unsigned long )d->rehashidx); while (d->ht[0 ].table[d->rehashidx] == NULL ) d->rehashidx++; de = d->ht[0 ].table[d->rehashidx]; while (de) { uint64_t h; nextde = de->next; h = dictHashKey(d, de->key) & d->ht[1 ].sizemask; de->next = d->ht[1 ].table[h]; d->ht[1 ].table[h] = de; d->ht[0 ].used--; d->ht[1 ].used++; de = nextde; } d->ht[0 ].table[d->rehashidx] = NULL ; d->rehashidx++; } return 1 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 static long _dictKeyIndex(dict *d, const void *key) { unsigned long h, idx, table; dictEntry *he; if (_dictExpandIfNeeded(d) == DICT_ERR) return -1 ; h = dictHashKey(d, key); for (table = 0 ; table <= 1 ; table++) { idx = h & d->ht[table].sizemask; he = d->ht[table].table[idx]; while (he) { if (dictCompareKeys(d, key, he->key)) return -1 ; he = he->next; } if (!dictIsRehashing(d)) break ; } return idx; }
其中用到了几个宏函数:
1 2 3 4 5 6 #define dictCompareKeys(d, key1, key2) \ (((d)->type->keyCompare) ? \ (d)->type->keyCompare((d)->privdata, key1, key2) : \ (key1) == (key2))
1 2 3 #define dictIsRehashing(d) ((d)->rehashidx != -1)
扩容函数_dictExpandIfNeeded见后。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 int dictAdd (dict *d, void *key, void *val) { dictEntry *entry = dictAddRaw(d,key); if (!entry) return DICT_ERR; dictSetVal(d, entry, val); return DICT_OK; }
其中调用了dictAddRaw函数,是真正添加键值对的函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 dictEntry *dictAddRaw (dict *d, void *key) { long index; dictEntry *entry; dictht *ht; if (dictIsRehashing(d)) _dictRehashStep(d); if ((index = _dictKeyIndex(d, key)) == -1 ) return NULL ; ht = dictIsRehashing(d) ? &d->ht[1 ] : &d->ht[0 ]; entry = zmalloc(sizeof (*entry)); entry->next = ht->table[index]; ht->table[index] = entry; ht->used++; dictSetKey(d, entry, key); return entry; }
dictAddRaw函数中判断了字典是否在rehash,如果在rehash,则进行一次rehash,然后试着在表1中添加键值对,如果没有在rehash,则跳过此步骤,在表0中添加键值对。这一步的作用是,如果字典在rehash中,那么每次进行常用的查找、更新操作时,能够让哈希表自动从表0迁移到表1,加速rehash过程。
_dictRehashStep函数如下:
1 2 3 4 5 6 7 static void _dictRehashStep(dict *d) { if (d->iterators == 0 ) dictRehash(d,1 ); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 dictEntry *dictFind (dict *d, const void *key) { dictEntry *he; uint64_t h, idx, table; if (d->ht[0 ].size == 0 ) return NULL ; if (dictIsRehashing(d)) _dictRehashStep(d); h = dictHashKey(d, key); for (table = 0 ; table <= 1 ; table++) { idx = h & d->ht[table].sizemask; he = d->ht[table].table[idx]; while (he) { if (dictCompareKeys(d, key, he->key)) return he; he = he->next; } if (!dictIsRehashing(d)) return NULL ; } return NULL ; }
1 2 3 4 5 6 void *dictFetchValue (dict *d, const void *key) { dictEntry *he; he = dictFind(d,key); return he ? dictGetVal(he) : NULL ; }
dictGetVal为宏函数:
1 #define dictGetVal(he) ((he)->v.val)
注意,需要释放哈希节点(dictEntry)的内存,同时,键和值如果是引用类型的指针的话(例如字符串),还需要释放这一片内存,此时需要调用在dictType注册好的键和值销毁函数。
1 2 3 4 5 6 7 8 9 int dictDelete (dict *ht, const void *key) { return dictGenericDelete(ht,key,0 ); } int dictDeleteNoFree (dict *ht, const void *key) { return dictGenericDelete(ht,key,1 ); }
两者都调用了dictGenericDelete函数,是真正执行释放内存的函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 static int dictGenericDelete (dict *d, const void *key, int nofree) { uint64_t h, idx; dictEntry *he, *prevHe; int table; if (d->ht[0 ].size == 0 ) return DICT_ERR; if (dictIsRehashing(d)) _dictRehashStep(d); h = dictHashKey(d, key); for (table = 0 ; table <= 1 ; table++) { idx = h & d->ht[table].sizemask; he = d->ht[table].table[idx]; prevHe = NULL ; while (he) { if (dictCompareKeys(d, key, he->key)) { if (prevHe) prevHe->next = he->next; else d->ht[table].table[idx] = he->next; if (!nofree) { dictFreeKey(d, he); dictFreeVal(d, he); } zfree(he); d->ht[table].used--; return DICT_OK; } prevHe = he; he = he->next; } if (!dictIsRehashing(d)) break ; } return DICT_ERR; }
dictFreeKey和dictFreeVal为宏函数:
1 2 3 4 5 6 7 #define dictFreeKey(d, entry) \ if ((d)->type->keyDestructor) \ (d)->type->keyDestructor((d)->privdata, (entry)->key) #define dictFreeVal(d, entry) \ if ((d)->type->valDestructor) \ (d)->type->valDestructor((d)->privdata, (entry)->v.val)
为了让哈希表的负载因子(load factor)维持在一个合理的范围之内,当哈希表保存的键值对数量太多或者太少时,程序需要对哈希表的大小进行相应的扩展或者收缩。收缩和扩展可以通过rehash来完成。
负载因子:过高的负载因子会导致hash冲突的增多,而如果把负载因子设置的过低,则会导致哈希表的频繁扩容,损耗性能。
1 load_factor = ht[0 ].used / ht[0 ].size;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 int dictExpand (dict *d, unsigned long size) { dictht n; unsigned long realsize = _dictNextPower(size); if (dictIsRehashing(d) || d->ht[0 ].used > size) return DICT_ERR; n.size = realsize; n.sizemask = realsize-1 ; n.table = zcalloc(realsize*sizeof (dictEntry*)); n.used = 0 ; if (d->ht[0 ].table == NULL ) { d->ht[0 ] = n; return DICT_OK; } d->ht[1 ] = n; d->rehashidx = 0 ; return DICT_OK; }
其中调用了_dictNextPower函数来确定扩容的大小,限制为$2^n$:
1 2 3 4 5 6 7 8 9 10 static unsigned long _dictNextPower(unsigned long size) { unsigned long i = DICT_HT_INITIAL_SIZE; if (size >= LONG_MAX) return LONG_MAX; while (1 ) { if (i >= size) return i; i *= 2 ; } }
dictResize函数将表的大小调整为包含所有元素的最小大小:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int dictResize (dict *d) { int minimal; if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR; minimal = d->ht[0 ].used; if (minimal < DICT_HT_INITIAL_SIZE) minimal = DICT_HT_INITIAL_SIZE; return dictExpand(d, minimal); }
dict_can_resize定义:
1 static int dict_can_resize = 1 ;
可以通过下列函数打开和关闭:
1 2 3 4 5 6 7 void dictEnableResize (void ) { dict_can_resize = 1 ; } void dictDisableResize (void ) { dict_can_resize = 0 ; }
在函数_dictKeyIndex(计算键的索引)中,判断了是否需要进行扩容:
1 2 if (_dictExpandIfNeeded(d) == DICT_ERR) return -1 ;
该函数实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 static int _dictExpandIfNeeded(dict *d) { if (dictIsRehashing(d)) return DICT_OK; if (d->ht[0 ].size == 0 ) return dictExpand(d, DICT_HT_INITIAL_SIZE); if (d->ht[0 ].used >= d->ht[0 ].size && (dict_can_resize || d->ht[0 ].used/d->ht[0 ].size > dict_force_resize_ratio)) { return dictExpand(d, d->ht[0 ].used*2 ); } return DICT_OK; }
dict_force_resize_ratio为负载因子的阈值:
1 static unsigned int dict_force_resize_ratio = 5 ;
迭代器相关的函数,略
销毁哈希表和字典,略
哈希函数
redis提供了两种哈希函数来计算键的哈希值,分别是Thomas Wang's 32 bit Mix Function和MurmurHash2。
2.4 压缩列表 2.4.1 定义 源码所在文件:ziplist.h
3 对象 源码所在文件:redis.h(定义),object.c(操作)
3.1 定义 redisObject类型结构体:
1 2 3 4 5 6 7 8 #define REDIS_LRU_BITS 24 typedef struct redisObject { unsigned type:4 ; unsigned encoding:4 ; unsigned lru:REDIS_LRU_BITS; int refcount; void *ptr; } robj;
unsigned若省略后一个关键字,大多数编译器都会认为是unsigned int。:4表示强制让unsigned int(一般占用8位)只占用4位。type取值:
1 2 3 4 5 6 #define REDIS_STRING 0 #define REDIS_LIST 1 #define REDIS_SET 2 #define REDIS_ZSET 3 #define REDIS_HASH 4
1 2 3 4 5 6 7 8 #define REDIS_ENCODING_RAW 0 #define REDIS_ENCODING_INT 1 #define REDIS_ENCODING_HT 2 #define REDIS_ENCODING_ZIPMAP 3 #define REDIS_ENCODING_LINKEDLIST 4 #define REDIS_ENCODING_ZIPLIST 5 #define REDIS_ENCODING_INTSET 6 #define REDIS_ENCODING_SKIPLIST 7
3.2 操作 创建对象:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 robj *createObject (int type, void *ptr) { robj *o = zmalloc(sizeof (*o)); o->type = type; o->encoding = REDIS_ENCODING_RAW; o->ptr = ptr; o->refcount = 1 ; o->lru = server.lruclock; return o; }
3.2.1 字符串对象
1 2 3 4 5 6 7 8 9 robj *createStringObject (char *ptr, size_t len) { return createObject(REDIS_STRING,sdsnewlen(ptr,len)); }
从long long类型(一般占用8个字节)来创建string对象:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 robj *createStringObjectFromLongLong (long long value) { robj *o; if (value >= 0 && value < REDIS_SHARED_INTEGERS) { incrRefCount(shared.integers[value]); o = shared.integers[value]; } else { if (value >= LONG_MIN && value <= LONG_MAX) { o = createObject(REDIS_STRING, NULL ); o->encoding = REDIS_ENCODING_INT; o->ptr = (void *)((long )value); } else { o = createObject(REDIS_STRING,sdsfromlonglong(value)); } } return o; }
其中变量redis.c/share是全局变量,用于记录共享对象,定义为:
1 struct sharedObjectsStruct shared ;
结构体redis.h/sharedObjectsStruct定义为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 struct sharedObjectsStruct { robj *crlf, *ok, *err, *emptybulk, *czero, *cone, *cnegone, *pong, *space, *colon, *nullbulk, *nullmultibulk, *queued, *emptymultibulk, *wrongtypeerr, *nokeyerr, *syntaxerr, *sameobjecterr, *outofrangeerr, *noscripterr, *loadingerr, *slowscripterr, *bgsaveerr, *masterdownerr, *roslaveerr, *execaborterr, *noautherr, *noreplicaserr, *oomerr, *plus, *messagebulk, *pmessagebulk, *subscribebulk, *unsubscribebulk, *psubscribebulk, *punsubscribebulk, *del, *rpop, *lpop, *lpush, *emptyscan, *minstring, *maxstring, *select[REDIS_SHARED_SELECT_CMDS], *integers[REDIS_SHARED_INTEGERS], *mbulkhdr[REDIS_SHARED_BULKHDR_LEN], *bulkhdr[REDIS_SHARED_BULKHDR_LEN]; };
以成员robj *integers[REDIS_SHARED_INTEGERS]为例,integers是一个大小为REDIS_SHARED_INTEGERS的数组,数组元素为robj *;
object.c/incrRefCount函数用于增加对象的引用计数:
1 2 3 void incrRefCount (robj *o) { o->refcount++; }
相应的还有减少对象引用计数的函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 void decrRefCount (robj *o) { if (o->refcount <= 0 ) redisPanic("decrRefCount against refcount <= 0" ); if (o->refcount == 1 ) { switch (o->type) { case REDIS_STRING: freeStringObject(o); break ; case REDIS_LIST: freeListObject(o); break ; case REDIS_SET: freeSetObject(o); break ; case REDIS_ZSET: freeZsetObject(o); break ; case REDIS_HASH: freeHashObject(o); break ; default : redisPanic("Unknown object type" ); break ; } zfree(o); } else { o->refcount--; } } void decrRefCountVoid (void *o) { decrRefCount(o); } robj *resetRefCount (robj *obj) { obj->refcount = 0 ; return obj; }
1 2 3 4 5 6 robj *dupStringObject (robj *o) { redisAssertWithInfo(NULL ,o,o->encoding == REDIS_ENCODING_RAW); return createStringObject(o->ptr,sdslen(o->ptr)); }
1 2 3 4 5 6 void freeStringObject (robj *o) { if (o->encoding == REDIS_ENCODING_RAW) { sdsfree(o->ptr); } }
3.2.2 列表对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 robj *createListObject (void ) { list *l = listCreate(); robj *o = createObject(REDIS_LIST,l); listSetFreeMethod(l,decrRefCountVoid); o->encoding = REDIS_ENCODING_LINKEDLIST; return o; }
其中adlist.h/listSetFreeMethod是一个宏函数:
1 #define listSetFreeMethod(l,m) ((l)->free = (m))
作用是将l的结构体成员free函数指针指向为m函数。
free成员是一个函数指针,返回值为void,参数为void*的指针:
1 void (*free )(void *ptr);
于是,这里是将l的free函数指针指向void decrRefCountVoid(void *o)函数。decrRefCountVoid用于减少引用计数,实际上它又调用了decrRefCount,详见3.2.1节。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void freeListObject (robj *o) { switch (o->encoding) { case REDIS_ENCODING_LINKEDLIST: listRelease((list *) o->ptr); break ; case REDIS_ENCODING_ZIPLIST: zfree(o->ptr); break ; default : redisPanic("Unknown list encoding type" ); } }
adlist.c/listRelease函数如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 void listRelease (list *list ) { unsigned long len; listNode *current, *next; current = list ->head; len = list ->len; while (len--) { next = current->next; if (list ->free ) list ->free (current->value); zfree(current); current = next; } zfree(list ); }
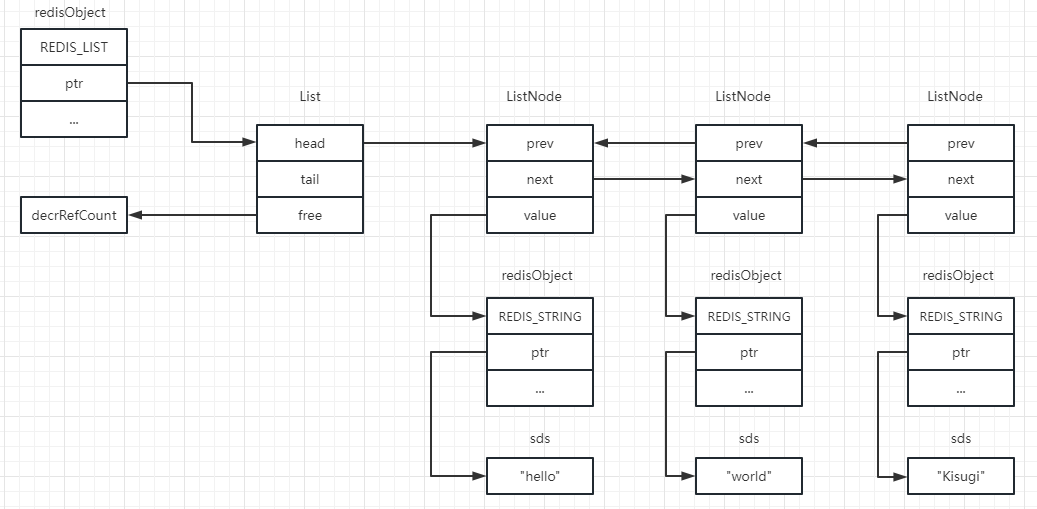
这里除了需要释放节点本身(ListNode)占用的内存,还需要调用list->free原因在于ListNode的值void *value可能会指向redis对象(如果是redis对象,则只能是字符串对象),这一片内存也需要释放,如图所示。
当调用:
1 2 3 if (list ->free ) list ->free (current->value);decrRefCount(current->value);
进入decrRefCount函数内,如果引用计数为1,则释放:
1 case REDIS_STRING: freeStringObject(o); break ;
如果字符串对象是raw编码,则进入freeStringObject后会执行:
例如图中hello的那片区域。最后decrRefCount会释放该redis对象本身的内存,例如第一个编码为REDIS_STRING的对象。
如果引用大于1,说明还有其他对象引用它,则只减去一个引用计数。
3.2.3 哈希对象
1 2 3 4 5 6 7 8 9 robj *createHashObject (void ) { unsigned char *zl = ziplistNew(); robj *o = createObject(REDIS_HASH, zl); o->encoding = REDIS_ENCODING_ZIPLIST; return o; }
1 2 3 4 5 6 7 8 9 10 11 12 13 void freeHashObject (robj *o) { switch (o->encoding) { case REDIS_ENCODING_HT: dictRelease((dict*) o->ptr); break ; case REDIS_ENCODING_ZIPLIST: zfree(o->ptr); break ; default : redisPanic("Unknown hash encoding type" ); break ; } }
4 数据库 源码所在文件:redis.h(数据库定义)
4.1 定义 数据库结构体定义:
1 2 3 4 5 6 7 8 9 typedef struct redisDb { dict *dict; dict *expires; dict *blocking_keys; dict *ready_keys; dict *watched_keys; int id; long long avg_ttl; } redisDb;
它作为redisServer结构体中的成员存在:
1 2 3 4 5 6 7 struct redisServer { redisDb *db; int dnum; };
4.2 操作 源码所在文件:db.c(相关操作)
4.2.1 5 RDB持久化 6 AOF持久化 7 事件/客户端/服务器 7.0 程序入口和服务器初始化
redis服务器程序入口函数位于redis.c/main:
1 2 3 4 5 6 7 8 9 10 11 12 13 int main (int argc, char **argv) { initServer(); aeMain(server.el); return 0 ; }
7.1 事件 源码位置:ae.h,ae.c
7.1.1 ae.h 核心结构体:aeEventLoop
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 #ifndef __AE_H__ #define __AE_H__ #define AE_OK 0 #define AE_ERR -1 #define AE_NONE 0 #define AE_READABLE 1 #define AE_WRITABLE 2 #define AE_FILE_EVENTS 1 #define AE_TIME_EVENTS 2 #define AE_ALL_EVENTS (AE_FILE_EVENTS|AE_TIME_EVENTS) #define AE_DONT_WAIT 4 #define AE_NOMORE -1 #define AE_NOTUSED(V) ((void) V) struct aeEventLoop ;typedef void aeFileProc (struct aeEventLoop *eventLoop, int fd, void *clientData, int mask) ;typedef int aeTimeProc (struct aeEventLoop *eventLoop, long long id, void *clientData) ;typedef void aeEventFinalizerProc (struct aeEventLoop *eventLoop, void *clientData) ;typedef void aeBeforeSleepProc (struct aeEventLoop *eventLoop) ;typedef struct aeFileEvent { int mask; aeFileProc *rfileProc; aeFileProc *wfileProc; void *clientData; } aeFileEvent; typedef struct aeTimeEvent { long long id; long when_sec; long when_ms; aeTimeProc *timeProc; aeEventFinalizerProc *finalizerProc; void *clientData; struct aeTimeEvent *next ; } aeTimeEvent; typedef struct aeFiredEvent { int fd; int mask; } aeFiredEvent; typedef struct aeEventLoop { int maxfd; int setsize; long long timeEventNextId; time_t lastTime; aeFileEvent *events; aeFiredEvent *fired; aeTimeEvent *timeEventHead; int stop; void *apidata; aeBeforeSleepProc *beforesleep; } aeEventLoop; aeEventLoop *aeCreateEventLoop (int setsize) ; void aeDeleteEventLoop (aeEventLoop *eventLoop) ;void aeStop (aeEventLoop *eventLoop) ;int aeCreateFileEvent (aeEventLoop *eventLoop, int fd, int mask, aeFileProc *proc, void *clientData) ;void aeDeleteFileEvent (aeEventLoop *eventLoop, int fd, int mask) ;int aeGetFileEvents (aeEventLoop *eventLoop, int fd) ;long long aeCreateTimeEvent (aeEventLoop *eventLoop, long long milliseconds, aeTimeProc *proc, void *clientData, aeEventFinalizerProc *finalizerProc) ;int aeDeleteTimeEvent (aeEventLoop *eventLoop, long long id) ;int aeProcessEvents (aeEventLoop *eventLoop, int flags) ;int aeWait (int fd, int mask, long long milliseconds) ;void aeMain (aeEventLoop *eventLoop) ;char *aeGetApiName (void ) ;void aeSetBeforeSleepProc (aeEventLoop *eventLoop, aeBeforeSleepProc *beforesleep) ;int aeGetSetSize (aeEventLoop *eventLoop) ;int aeResizeSetSize (aeEventLoop *eventLoop, int setsize) ;#endif
7.1.2 ae.c 监听套接字(副套接字)上的文件读写事件是否发生,本质上是监听套接字上的读写是否准备就绪。前者的实现依赖于后者,后者的实现依赖于IO多路复用技术,例如select,epoll等,以select为例:
ae.c/aeCreateFileEvent依赖于ae_select.c/aeApiAddEvent,后者实际上就是FD_SET;ae.c/aeDeleteFileEvent依赖于ae_select.c/aeApiDelEvent,后者使用了FD_CLR来清除fd上的读写监听。ae.c/aeProcessEvents依赖于ae_select.c/aeApiPoll,后者使用了select调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 #ifdef HAVE_EVPORT #include "ae_evport.c" #else #ifdef HAVE_EPOLL #include "ae_epoll.c" #else #ifdef HAVE_KQUEUE #include "ae_kqueue.c" #else #include "ae_select.c" #endif #endif #endif aeEventLoop *aeCreateEventLoop (int setsize) { aeEventLoop *eventLoop; int i; if ((eventLoop = zmalloc(sizeof (*eventLoop))) == NULL ) goto err; eventLoop->events = zmalloc(sizeof (aeFileEvent)*setsize); eventLoop->fired = zmalloc(sizeof (aeFiredEvent)*setsize); if (eventLoop->events == NULL || eventLoop->fired == NULL ) goto err; eventLoop->setsize = setsize; eventLoop->lastTime = time(NULL ); eventLoop->timeEventHead = NULL ; eventLoop->timeEventNextId = 0 ; eventLoop->stop = 0 ; eventLoop->maxfd = -1 ; eventLoop->beforesleep = NULL ; if (aeApiCreate(eventLoop) == -1 ) goto err; for (i = 0 ; i < setsize; i++) eventLoop->events[i].mask = AE_NONE; return eventLoop; err: if (eventLoop) { zfree(eventLoop->events); zfree(eventLoop->fired); zfree(eventLoop); } return NULL ; } int aeGetSetSize (aeEventLoop *eventLoop) { return eventLoop->setsize; } void aeDeleteEventLoop (aeEventLoop *eventLoop) { aeApiFree(eventLoop); zfree(eventLoop->events); zfree(eventLoop->fired); zfree(eventLoop); } int aeCreateFileEvent (aeEventLoop *eventLoop, int fd, int mask, aeFileProc *proc, void *clientData) { if (fd >= eventLoop->setsize) { errno = ERANGE; return AE_ERR; } aeFileEvent *fe = &eventLoop->events[fd]; if (aeApiAddEvent(eventLoop, fd, mask) == -1 ) return AE_ERR; fe->mask |= mask; if (mask & AE_READABLE) fe->rfileProc = proc; if (mask & AE_WRITABLE) fe->wfileProc = proc; fe->clientData = clientData; if (fd > eventLoop->maxfd) eventLoop->maxfd = fd; return AE_OK; } void aeDeleteFileEvent (aeEventLoop *eventLoop, int fd, int mask) { if (fd >= eventLoop->setsize) return ; aeFileEvent *fe = &eventLoop->events[fd]; if (fe->mask == AE_NONE) return ; aeApiDelEvent(eventLoop, fd, mask); fe->mask = fe->mask & (~mask); if (fd == eventLoop->maxfd && fe->mask == AE_NONE) { int j; for (j = eventLoop->maxfd-1 ; j >= 0 ; j--) if (eventLoop->events[j].mask != AE_NONE) break ; eventLoop->maxfd = j; } } int aeGetFileEvents (aeEventLoop *eventLoop, int fd) { if (fd >= eventLoop->setsize) return 0 ; aeFileEvent *fe = &eventLoop->events[fd]; return fe->mask; } int aeProcessEvents (aeEventLoop *eventLoop, int flags) { int processed = 0 , numevents; if (!(flags & AE_TIME_EVENTS) && !(flags & AE_FILE_EVENTS)) return 0 ; if (eventLoop->maxfd != -1 || ((flags & AE_TIME_EVENTS) && !(flags & AE_DONT_WAIT))) { numevents = aeApiPoll(eventLoop, tvp); for (j = 0 ; j < numevents; j++) { aeFileEvent *fe = &eventLoop->events[eventLoop->fired[j].fd]; int mask = eventLoop->fired[j].mask; int fd = eventLoop->fired[j].fd; int rfired = 0 ; if (fe->mask & mask & AE_READABLE) { rfired = 1 ; fe->rfileProc(eventLoop,fd,fe->clientData,mask); } if (fe->mask & mask & AE_WRITABLE) { if (!rfired || fe->wfileProc != fe->rfileProc) fe->wfileProc(eventLoop,fd,fe->clientData,mask); } processed++; } } if (flags & AE_TIME_EVENTS) processed += processTimeEvents(eventLoop); return processed; } void aeMain (aeEventLoop *eventLoop) { eventLoop->stop = 0 ; while (!eventLoop->stop) { if (eventLoop->beforesleep != NULL ) eventLoop->beforesleep(eventLoop); aeProcessEvents(eventLoop, AE_ALL_EVENTS); } }
7.1.3 ae_select.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 typedef struct aeApiState { fd_set rfds, wfds; fd_set _rfds, _wfds; } aeApiState; static int aeApiCreate (aeEventLoop *eventLoop) { aeApiState *state = zmalloc(sizeof (aeApiState)); if (!state) return -1 ; FD_ZERO(&state->rfds); FD_ZERO(&state->wfds); eventLoop->apidata = state; return 0 ; } static int aeApiResize (aeEventLoop *eventLoop, int setsize) { if (setsize >= FD_SETSIZE) return -1 ; return 0 ; } static void aeApiFree (aeEventLoop *eventLoop) { zfree(eventLoop->apidata); } static int aeApiAddEvent (aeEventLoop *eventLoop, int fd, int mask) { aeApiState *state = eventLoop->apidata; if (mask & AE_READABLE) FD_SET(fd,&state->rfds); if (mask & AE_WRITABLE) FD_SET(fd,&state->wfds); return 0 ; } static void aeApiDelEvent (aeEventLoop *eventLoop, int fd, int mask) { aeApiState *state = eventLoop->apidata; if (mask & AE_READABLE) FD_CLR(fd,&state->rfds); if (mask & AE_WRITABLE) FD_CLR(fd,&state->wfds); } static int aeApiPoll (aeEventLoop *eventLoop, struct timeval *tvp) { aeApiState *state = eventLoop->apidata; int retval, j, numevents = 0 ; memcpy (&state->_rfds,&state->rfds,sizeof (fd_set)); memcpy (&state->_wfds,&state->wfds,sizeof (fd_set)); retval = select(eventLoop->maxfd+1 , &state->_rfds,&state->_wfds,NULL ,tvp); if (retval > 0 ) { for (j = 0 ; j <= eventLoop->maxfd; j++) { int mask = 0 ; aeFileEvent *fe = &eventLoop->events[j]; if (fe->mask == AE_NONE) continue ; if (fe->mask & AE_READABLE && FD_ISSET(j,&state->_rfds)) mask |= AE_READABLE; if (fe->mask & AE_WRITABLE && FD_ISSET(j,&state->_wfds)) mask |= AE_WRITABLE; eventLoop->fired[numevents].fd = j; eventLoop->fired[numevents].mask = mask; numevents++; } } return numevents; } static char *aeApiName (void ) { return "select" ; }
7.1.4 networking.c Redis 将客户端的创建、消息回复等功能,实现在了 networking.c 文件中。Redis 对 TCP 网络通信的 Socket 连接、设置等操作进行了封装,这些封装后的函数实现在 anet.h/anet.c 中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 redisClient *createClient (int fd) { redisClient *c = zmalloc(sizeof (redisClient)); if (fd != -1 ) { anetNonBlock(NULL ,fd); anetEnableTcpNoDelay(NULL ,fd); if (server.tcpkeepalive) anetKeepAlive(NULL ,fd,server.tcpkeepalive); if (aeCreateFileEvent(server.el,fd,AE_READABLE,readQueryFromClient,c) == AE_ERR) { close(fd); zfree(c); return NULL ; } } c->id = server.next_client_id++; c->fd = fd; return c; } #define MAX_ACCEPTS_PER_CALL 1000 static void acceptCommonHandler (int fd, int flags) { redisClient *c; if ((c = createClient(fd)) == NULL ) { redisLog(REDIS_WARNING, "Error registering fd event for the new client: %s (fd=%d)" , strerror(errno),fd); close(fd); return ; } if (listLength(server.clients) > server.maxclients) { char *err = "-ERR max number of clients reached\r\n" ; if (write(c->fd,err,strlen (err)) == -1 ) { } server.stat_rejected_conn++; freeClient(c); return ; } server.stat_numconnections++; c->flags |= flags; } void acceptTcpHandler (aeEventLoop *el, int fd, void *privdata, int mask) { int cport, cfd, max = MAX_ACCEPTS_PER_CALL; char cip[REDIS_IP_STR_LEN]; REDIS_NOTUSED(el); REDIS_NOTUSED(mask); REDIS_NOTUSED(privdata); while (max--) { cfd = anetTcpAccept(server.neterr, fd, cip, sizeof (cip), &cport); if (cfd == ANET_ERR) { if (errno != EWOULDBLOCK) redisLog(REDIS_WARNING, "Accepting client connection: %s" , server.neterr); return ; } redisLog(REDIS_VERBOSE,"Accepted %s:%d" , cip, cport); acceptCommonHandler(cfd,0 ); } }
上面是连接应答处理器的代码,即服务器端的accept的封装,这里调用了anet.c/anetTcpAccept,而anet.c/anetTcpAccept又调用了anet.c/anetGenericAccept,accept调用就在最后一个函数中,相关代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 static int anetGenericAccept (char *err, int s, struct sockaddr *sa, socklen_t *len) { int fd; while (1 ) { fd = accept(s,sa,len); if (fd == -1 ) { if (errno == EINTR) continue ; else { anetSetError(err, "accept: %s" , strerror(errno)); return ANET_ERR; } } break ; } return fd; } int anetTcpAccept (char *err, int s, char *ip, size_t ip_len, int *port) { int fd; struct sockaddr_storage sa ; socklen_t salen = sizeof (sa); if ((fd = anetGenericAccept(err,s,(struct sockaddr*)&sa,&salen)) == -1 ) return ANET_ERR; if (sa.ss_family == AF_INET) { struct sockaddr_in *s =struct sockaddr_in *)&sa; if (ip) inet_ntop(AF_INET,(void *)&(s->sin_addr),ip,ip_len); if (port) *port = ntohs(s->sin_port); } else { struct sockaddr_in6 *s = (struct sockaddr_in6 *)&sa; if (ip) inet_ntop(AF_INET6,(void *)&(s->sin6_addr),ip,ip_len); if (port) *port = ntohs(s->sin6_port); } return fd; }
其中,地址的表示使用了sockaddr_storage,它在<netinet/in.h>头文件中定义:是升级版的sockaddr。
1 2 3 4 struct sockaddr_storage { uint8_t ss_len; sa_family_t ss_family; };
这是一般结构,实际使用时要根据协议族强转为对应协议的地址类型。
7.2 客户端 redis客户端是不定的,可以使用redis源码自带的客户端,也可以使用外部的客户端。但底层调用了connect函数来与redis服务器连接。redis服务器使用一些结构体来存储客户端的属性和客户端发送来的数据,需要一些函数来操作客户端相关的资源。
7.2.1 客户端属性 结构体定义在redis.h/redisClient:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 typedef struct redisClient { uint64_t id; int fd; redisDb *db; int dictid; robj *name; sds querybuf; size_t querybuf_peak; int argc; robj **argv; struct redisCommand *cmd , *lastcmd ; int reqtype; int multibulklen; long bulklen; list *reply; unsigned long reply_bytes; int sentlen; time_t ctime; time_t lastinteraction; time_t obuf_soft_limit_reached_time; int flags; int authenticated; int replstate; int repl_put_online_on_ack; int repldbfd; off_t repldboff; off_t repldbsize; sds replpreamble; long long reploff; long long repl_ack_off; long long repl_ack_time; long long psync_initial_offset; char replrunid[REDIS_RUN_ID_SIZE+1 ]; int slave_listening_port; int slave_capa; multiState mstate; blockingState bpop; list *watched_keys; dict *pubsub_channels; list *pubsub_patterns; sds peerid; int bufpos; char buf[REDIS_REPLY_CHUNK_BYTES]; } redisClient;
7.2.2 创建客户端 7.3 服务器 7.3.1 发送数据